Implicit regularization in Heavy-ball momentum accelerated stochastic gradient descent
Abstract
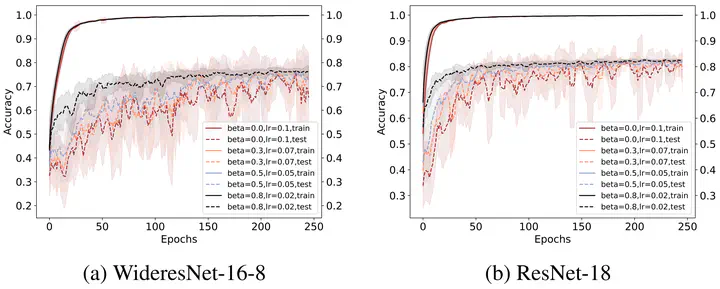
It is well known that the finite step-size in Gradient Descent (GD) implicitly regularizes solutions to flatter minima. A natural question to ask is Does the momentum parameter play a role in implicit regularization in Heavy-ball (H.B) momentum accelerated gradient descent (GD+M)? To answer this question, first, we show that the discrete H.B momentum update (GD+M) follows a continuous trajectory induced by a modified loss, which consists of an original loss and an implicit regularizer. Then, we show that this implicit regularizer for (GD+M) is stronger than that of (GD) by factor, thus explaining why (GD+M) shows better generalization performance and higher test accuracy than (GD). Furthermore, we extend our analysis to the stochastic version of gradient descent with momentum (SGD+M) and characterize the continuous trajectory of the update of (SGD+M) in a pointwise sense. We explore the implicit regularization in (SGD+M) and (GD+M) through a series of experiments validating our theory.